
Evaluation of AI/ML Based Post-Filter Enhancement in Opus Codec Version 1.5
Sukumar Arasada, Mohan Prasad Sappidi, and Basharath Hussain Khaja
1. Introduction
Opus codec [1] is rightly touted as the Swiss Army Knife of audio codecs. Its flexibility and versatility is on par with the 3GPP EVS Standard [2]. It automatically detects whether the input is speech or music and selects an appropriate algorithm for optimal coding. It supports variable frame lengths, ranging from 2.5 ms to 60 ms, to accommodate low-delay real-time applications as well as offline storage applications. It can operate on mono- or stereo-signals sampled at 8 KHz to 48 KHz to generate compressed bit-streams in the range of 6 kbps to 510 kbps respectively. It supports constant bit-rate, variable bit-rate, and discontinuous transmission modes. It offers a complexity “knob” to fine-tune the trade-off between complexity and quality. For robustness against frame corruption or losses, it provides an FEC algorithm at the encoder and a packet loss concealment algorithm at the deocder. Opus is widely accepted as the de-facto open-source codec for speech and audio applications. It is also a mandatory codec in Google’s WebRTC framework.
Over the last decade, several Artificial Intelligence (AI) and Machine Learning (ML) techniques have been proposed for enhancing speech coding performance. These techniques can be broadly classified as follows:
- End-to-end neural speech coding wherein the entire encoding and decoding algorithms are implemented using neural networks [3, 4, 5, 6].
- Traditional encoding and decoding methods (Linear-Prediction Coding, analysis-by-synthesis algorithms, or transform coding) are enhanced with neural-network based algorithms to improve the perceptual quality of decoded speech [7, 8, 9].
2. Evaluation of LACE Algorithm
Baseline Opus codec does not use the classical adaptive post-filter, probably due to patent and other licensing restrictions. Instead in Opus version 1.5, for the first time, a DNN based post-filter denoising algorithm called LACE has been introduced as an optional feature that can enabled at compile time. At run-time, LACE is used only if the “complexity” parameter in decoder is set to 6 (in a scale of 1 to 10) for wide-band use cases. Reference [8] provides a detailed description of the LACE algorithm.
Floating-point implementation of Libopus version 1.5.2 [15] with the release date of 12th April, 2024 was used in our evaluation. A subset of speech recordings available here [16], was used in our study. Our test set has five male and five female recordings in English, are sampled at 16000 Hz, has an average duration of 23 seconds, and can be downloaded from here [17]. We encoded these input test vectors using bit-rates ranging from 6 kbps to 22 kbps. An example command used for encoding a test vector is given below:
./opus_demo -e voip 16000 1 6000 -bandwidth WB -framesize 20 -complexity 3 -inbandfec -loss 0 input.wav output.cod
Once the bit-streams are generated, we decode the bitstreams with and without enabling the LACE algorithm. An example command used for decoding without enabling the LACE algorithm is given below:
./opus_demo -d 16000 1 -inbandfec -loss 0 output.cod baseline_output.pcm
The following command was used for decoding by enabling LACE:
./opus_demo -d 16000 1 -dec_complexity 6 -inbandfec -loss 0 output.cod lace_output.cod
2.1 Speech Quality
Using ITU-T P.862 [18],
we generated the PESQ scores between the decoded output and encoder
input files. We then mapped the PESQ scores to MOS-LQO scores as
specified in ITU-T P.862.1 [19].
Figure 1 below shows the plot of average MOS-LQO scores obtained from
the test set for bit-rates ranging from 6 kbps to 22 kbps. We observe
that at low bit-rates, the MOS-LQO scores obtained using LACE are
better than the baseline Opus decoder. Note that scores with
differences of ±
0.1 are considered to be statistically significant. At 6 kbps and 7
kbps bit-rates, the difference in MOS-LQO score is 0.4 and at higher
bit-rates, at 22 kbps, there is no improvement in speech quality.
Clearly, at low bit-rates LACE algorithm outperforms the baseline
Opus decoder. The results are in line with [8],
which also provides
subjective evaluation results using crowdsourcing methodology [20].
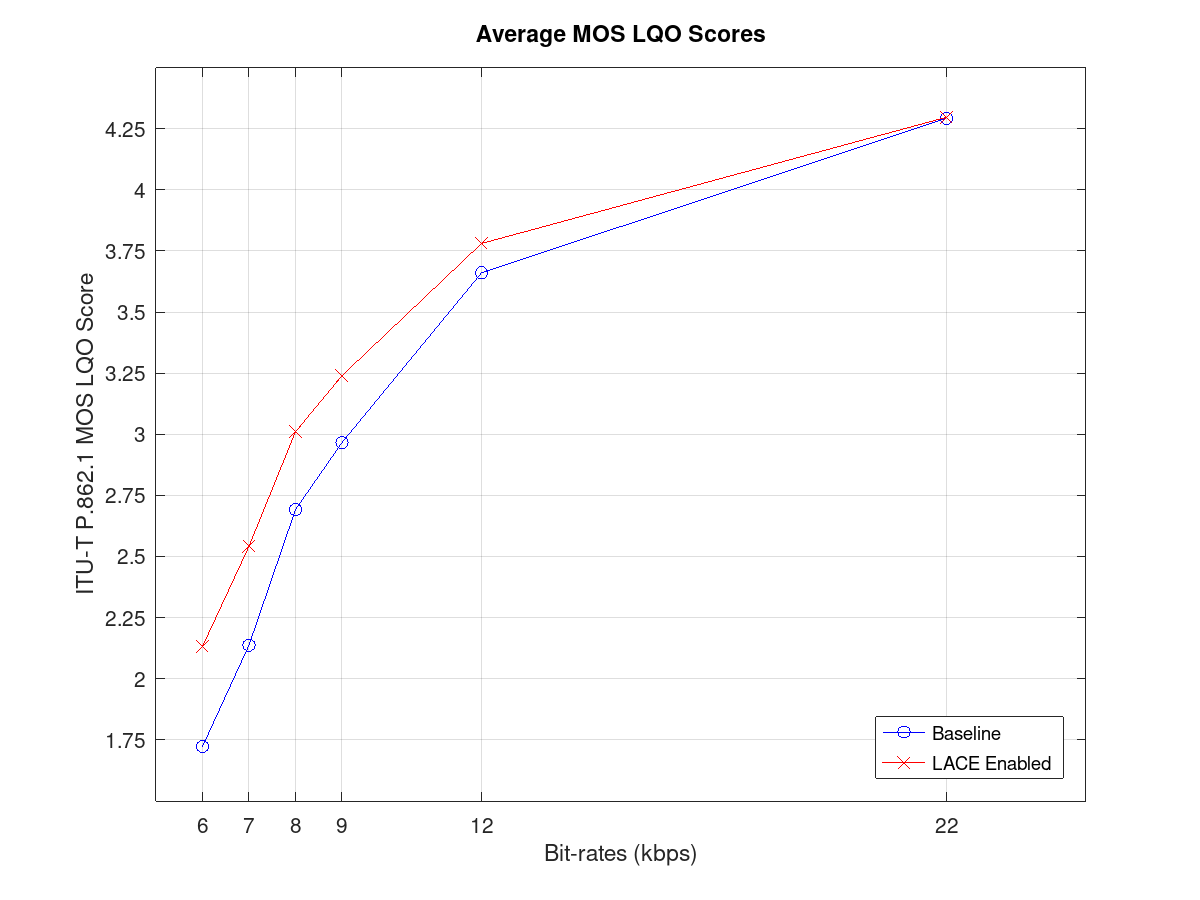
Figure
1: Comparison of average
MOS-LQO Scores between
baseline and LACE enabled Opus Decoder.
2.2 Complexity
Table 1 provides the average CPU cycle load consumed by Opus decoder with and without LACE for the given test set. The Opus codec was compiled to run on X86-64 bit CPU architecture with AVX optimization enabled. The CPU cycles (MIPS) were measured on an Intel host machine with the following system configuration — Intel® Core™ i5-11400 CPU @ base frequency of 2.60 GHz, 8GB DDR4 @ 2667 MT/s, running Linux CentOS Stream 9.
|
Baseline Opus Decoder (MIPS) |
LACE enabled Opus Decoder (MIPS) |
|
1.3 |
5.4 |
Table 1: Comparison of CPU cycles (MIPS) between baseline and LACE enabled Opus Decoder
We observe that there is a four-fold increase in CPU cycle load when LACE is enabled. Note that LACE is a stand-alone block independent of the baseline Opus decoder. Encoder is not aware whether or not LACE is enabled at the receiver. LACE algorithm uses information already present in the baseline Opus encoded bit-stream. There is no additional side information from the encoder specifically for LACE. Therefore, the receiver can decide based on the local CPU load conditions, whether to enable LACE for better speech quality. However, for transcoding use cases, the increase in the computational complexity will reduce the overall channel density (number of simultaneous transcoding sessions per CPU). Enabling LACE will probably be a premium feature for the transcoding usecase.3. Conclusion
Speech coding using AI/ML techniques is an active research area. Although computationally more intensive than traditional techniques, they are now increasingly used in the next generation speech codecs. Opus codec version 1.5 has introduced a DNN based post-filtering algorithms called LACE. In this report, we present the results of our independent evaluation of the LACE enabled Opus decoder. Our results indicate that at low bit-rates, LACE performance significantly better than the baseline decoder. Our results corroborate with the results presented in [8 However, one must note the following:
- LACE enabled Opus decoder consumes four times more computational resources when compared to the baseline Opus decoder.
- Baseline Opus encoder does not use the classical adaptive post filter algorithm. It will be interesting to compare the performance between classical and LACE enabled Opus decoder.
-
A non-linear extension of LACE algorithm called NOLACE is also available in Opus codec version 1.5. We have not evaluated this extension in our study.
4. Acknowledgement
We thank Dr. Krishna Nagarajan for his guidance during the evaluation and in writing this report. For any queries, please contact support@couthit.com.